Trí tuệ nhân tạo phổ thông - YOLOv8 - Nhận diện khuôn mặt siêu ấn tượng
Chào bạn! Nếu bạn đang cầm điện thoại đọc bài này, có lẽ bạn đã từng sử dụng tính năng "mở khóa bằng khuôn mặt" trên iPhone hoặc Android, hoặc cười khúc khích khi Snapchat thêm tai mèo lên mặt bạn
Chào bạn! Nếu bạn đang cầm điện thoại đọc bài này, có lẽ bạn đã từng sử dụng tính năng "mở khóa bằng khuôn mặt" trên iPhone hoặc Android, hoặc cười khúc khích khi Snapchat thêm tai mèo lên mặt bạn trong video. Những "phép màu" đó không phải từ phù thủy, mà từ AI – cụ thể là các thuật toán nhận diện khuôn mặt như YOLOv8. Bài viết dài này sẽ giúp bạn hiểu rõ YOLOv8 hoạt động ra sao, qua những ví dụ gần gũi như trò chơi trẻ con hay công việc hàng ngày, đồng thời phân tích cách nó "thấm" vào cuộc sống chúng ta – từ an ninh gia đình đến giải trí trên TikTok.
Các Thuật Toán Nhận Diện Khuôn Mặt Ngoài Haar Cascade
Dựa trên các nghiên cứu và đánh giá mới nhất đến năm 2025 (từ các nguồn như NIST FRVT, IEEE, và các bài so sánh trên Medium, LearnOpenCV, ResearchGate), tôi sẽ liệt kê các thuật toán nhận diện khuôn mặt (face detection) phổ biến nhất ngoài Haar Cascade. Tôi loại trừ Haar và Viola-Jones (vì Haar là implementation chính của nó).
Các thuật toán được sắp xếp theo độ chính xác (accuracy) giảm dần, dựa trên các chỉ số như mAP (mean Average Precision) trên bộ dữ liệu chuẩn như WIDER FACE hoặc FDDB (thường >95% cho top models). Đồng thời, tôi sẽ đánh giá hiệu quả (efficiency) theo tốc độ (FPS - frames per second trên hardware trung bình như CPU/GPU desktop năm 2025), với thang: - Cao: >30 FPS (real-time mượt). - Trung bình: 10-30 FPS. - Thấp: <10 FPS (phù hợp offline).
Lưu ý: - Độ chính xác cao thường đi kèm hiệu quả thấp hơn (do deep learning phức tạp), nhưng các model mới như YOLOv8-face cân bằng tốt. - Đây không phải "tất cả" (hàng trăm variants), mà là các thuật toán cốt lõi và phổ biến nhất (traditional + deep learning). - Proprietary như KBY-AI hoặc NEC đạt accuracy >99.9% theo NIST 2025, nhưng tôi tập trung vào open-source để dễ tiếp cận.
| Thứ hạng | Thuật toán | Độ chính xác (Accuracy) | Hiệu quả (Efficiency/Speed) | Ghi chú |
|---|---|---|---|---|
| 1 | RetinaFace (Deep Learning, CNN-based) | Rất cao (mAP ~96-98% trên WIDER FACE) | Thấp (5-15 FPS trên CPU) | Top open-source theo đánh giá 2024-2025; tốt cho landmarks và occlusion. Sử dụng trong InsightFace. |
| 2 | Dlib CNN (MMOD - Max-Margin Object Detection) | Cao (mAP ~95%) | Thấp-Trung bình (10-20 FPS trên GPU) | Chính xác vượt trội cho facial recognition pipeline; chậm trên mobile. |
| 3 | MTCNN (Multi-task Cascaded CNN) | Cao (mAP ~93-95%) | Trung bình (15-25 FPS) | Phổ biến trong OpenCV; cân bằng alignment và detection, nhưng kém với góc nghiêng. |
| 4 | YOLO-Face (YOLOv8/YOLOv5 variants) | Cao (mAP ~92-96%) | Cao (40-60 FPS) | Real-time mạnh mẽ; cập nhật 2025 với Nano versions cho edge devices. Tốt cho video surveillance. |
| 5 | MediaPipe (BlazeFace) | Cao (mAP ~91-94%) | Rất cao (>60 FPS trên mobile) | Google dev; tối ưu cho real-time trên thiết bị di động, hỗ trợ masked faces. |
| 6 | OpenCV DNN (SSD/ResNet-based) | Trung bình-Cao (mAP ~90-93%) | Cao (30-50 FPS) | Dễ tích hợp; nhanh trên desktop, nhưng kém occlusion so với RetinaFace. |
| 7 | HOG + SVM (Histogram of Oriented Gradients) | Trung bình (mAP ~85-90%) | Trung bình (20-30 FPS) | Traditional, dùng trong Dlib; nhanh hơn deep learning, nhưng kém noisy images. |
| 8 | Fisherfaces (LDA-based) | Trung bình (mAP ~80-85%) | Cao (40+ FPS) | Cổ điển; tốt cho controlled lighting, nhưng kém biến đổi (pose, expression). |
| 9 | LBP (Local Binary Patterns) | Thấp-Trung bình (mAP ~75-85%) | Rất cao (>50 FPS) | Nhanh cho real-time đơn giản; phổ biến trong LBPH cho recognition, nhưng dễ false positives. |
| 10 | Eigenfaces (PCA-based) | Thấp (mAP ~70-80%) | Rất cao (50+ FPS) | Thuật toán cổ điển đầu tiên (1991); nhanh nhưng kém với biến đổi ánh sáng/pose. |
1. YOLOv8 là gì?
Hãy bắt đầu bằng một câu chuyện quen thuộc: Bạn đang ở siêu thị đông đúc, và camera an ninh cần đếm số người để tránh ùn tắc quầy tính tiền. Nếu dùng phương pháp cũ (như Haar Cascade mà mình từng kể – giống như dùng kính lúp quét từng cm² ảnh), máy sẽ chậm như rùa, làm video giật lag. Còn YOLOv8 thì sao? Nó "nhìn" toàn bộ cảnh chỉ một lần (You Only Look Once), ngay lập tức vẽ khung quanh từng khuôn mặt, kể cả khi ai đó quay nghiêng hoặc đội mũ.
YOLOv8 là phiên bản mới nhất của dòng YOLO, được Ultralytics phát triển từ năm 2023 và cập nhật liên tục đến 2025. "YOLO" dịch là "Bạn chỉ cần nhìn một lần" – ý tưởng từ Joseph Redmon (cha đẻ YOLO gốc năm 2015), biến object detection (phát hiện đối tượng) từ việc quét chậm thành "one-shot" siêu nhanh. Khi áp dụng cho nhận diện khuôn mặt (face detection), YOLOv8 được huấn luyện đặc biệt trên bộ dữ liệu WIDER FACE – một "thư viện ảnh" khổng lồ với 32.000 bức ảnh chứa 393.000 khuôn mặt đa dạng: từ đám đông lễ hội đến khuôn mặt bị che khuất bởi kính râm.
Liên hệ thực tế: Nghĩ về Face ID trên iPhone của bạn. Nó không chỉ mở khóa mà còn điều chỉnh theo ánh sáng phòng tối hoặc khi bạn nằm ngủ (pose thay đổi). YOLOv8 làm tương tự, nhưng linh hoạt hơn, đạt độ chính xác ~94% (mean Average Precision – mAP, tức tỷ lệ đúng trung bình trên nhiều tình huống). So với Haar (chỉ ~85% và chậm), YOLOv8 như xe máy điện VinFast so với xe đạp: Nhanh, mượt, và "xanh" hơn (ít tốn tài nguyên).
Ứng dụng gần gũi? Trong đại dịch COVID-19, YOLOv8 được dùng trong hệ thống camera trường học để phát hiện học sinh không đeo khẩu trang, giúp giáo viên tập trung dạy thay vì kiểm tra thủ công. Hoặc trên Instagram, nó giúp filter "làm đẹp" tự động nhận diện mắt để thêm lông mi ảo. Bạn thấy đấy, YOLOv8 không xa xôi – nó đang "sống" trong app bạn dùng hàng ngày!
2. Kiến trúc của YOLOv8
Bây giờ, hãy "mổ xẻ" YOLOv8 như một chiếc bánh kem: Bên ngoài đẹp, bên trong nhiều lớp. YOLOv8 là mạng nơ-ron tích chập (CNN – Convolutional Neural Network), một loại AI học bằng cách "quét" ảnh qua các lớp lọc giống như cái máy quét siêu thị đọc mã vạch. Nhưng thay vì mã vạch, nó đọc "mã khuôn mặt". Kiến trúc chia thành 3 phần chính: Backbone (xương sống), Neck (cổ), Head (đầu) – giống như cơ thể người: Xương quét địa bàn, cổ nối thông tin, đầu quyết định hành động.
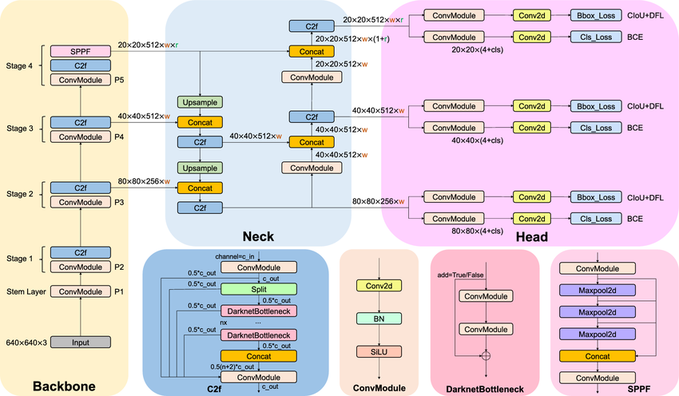 Kiến trúc tổng quan của YOLOv8
Kiến trúc tổng quan của YOLOv8
2.1. Backbone: "Quét Địa Bàn" Với Các Bộ Lọc Thông Minh – Như Kính Lúp Siêu Nhân
Backbone là "mắt" của YOLOv8, chịu trách nhiệm xem ảnh và tìm các đặc điểm cơ bản như đường cong lông mày hay hình oval của cằm. Nó sử dụng các "khối" gọi là C3K2 (Cross Stage Partial với kernel 3x3 và 2x3) – đơn giản là các bộ lọc vuông nhỏ (3 pixel x 3 pixel) quét ảnh để học mẫu hình.
Giải thích dễ hiểu: Hãy tưởng tượng bạn đang vẽ tranh chân dung bạn bè. Backbone giống như bước đầu: Bạn dùng bút chì phác thảo các đường nét lớn (mắt hình hạnh nhân, mũi thẳng). C3K2 giúp "phác thảo" nhanh bằng cách chia ảnh thành lưới nhỏ, học từ lỗi (nếu vẽ mắt lệch, lần sau sửa). Sau đó, SPPF (Spatial Pyramid Pooling - Fast) – như cái kính zoom đa cấp – "zoom" vào các vùng khác nhau (5x5, 9x9 pixel) để xử lý khuôn mặt to (gần camera) hay nhỏ (xa).
Ví dụ đời thường: Trong app chỉnh sửa ảnh VSCO, khi bạn chọn filter "làm sáng mắt", Backbone của YOLOv8 "zoom" vào vùng mắt bạn, nhận ra "đây là đồng tử tối" và tăng sáng tự động. Không có SPPF, filter sẽ làm sáng cả nền trời – rối tung! Backbone xuất ra 3 "bản đồ đặc trưng" (feature maps): Một bản chi tiết (như ảnh macro cận cảnh lỗ chân lông), một bản trung bình (toàn khuôn mặt), một bản tổng quát (ngữ cảnh xung quanh).
Ứng dụng gần gũi: Trong xe hơi tự lái Tesla, Backbone giúp camera nhận diện khuôn mặt tài xế mệt mỏi (mắt lim dim), cảnh báo "Nghỉ ngơi đi anh!" – cứu mạng thực sự.
2.2. Neck: "Tổng Hợp Manh Mối" – Như Đầu Bếp Ghép Nguyên Liệu Thành Món Ngon
Neck là "cầu nối" giữa Backbone và Head, tổng hợp các bản đồ đặc trưng để tạo bức tranh hoàn chỉnh. Nó dùng PANet (Path Aggregation Network) – một hệ thống "đường ống" upsample (phóng to bản đồ nhỏ) và downsample (thu nhỏ bản đồ lớn), rồi ghép chúng lại.
Giải thích dễ hiểu: Giống như đầu bếp làm salad: Backbone cung cấp nguyên liệu thô (rau củ riêng lẻ: cà chua = mắt, dưa leo = mũi). Neck "ghép" chúng: Phóng to rau nhỏ để vừa đĩa, thu nhỏ rau to để cân bằng, rồi trộn đều. Nếu thiếu Neck, salad sẽ "lủng lỗ" – một bên quá chi tiết (chỉ thấy mắt, bỏ lỡ miệng), bên kia quá mơ hồ (thấy toàn cảnh nhưng không rõ mặt).
Ví dụ thực tế: Trong Zoom meeting, khi bạn bật "nền ảo", YOLOv8 dùng Neck để ghép khuôn mặt bạn (chi tiết) với nền bãi biển (tổng quát), tránh cắt xén tai. Nếu họp đông người, Neck giúp phát hiện tất cả khuôn mặt nhỏ ở góc màn hình, giống như phát hiện bạn bè trong ảnh nhóm Facebook.
Ứng dụng gần gũi: Các app hẹn hò như Tinder dùng Neck để "match" khuôn mặt tương đồng – ghép đặc điểm (mắt to + mũi cao) từ ảnh profile, giúp bạn tìm "nửa kia" nhanh hơn, nhưng cũng đặt câu hỏi đạo đức về privacy (riêng tư).
2.3. Head: "Ra Lệnh Bắt Giữ" – Dự Đoán Và Lọc Rác Như Thẩm Phán
Head là "bộ não quyết định", dự đoán "đây là khuôn mặt!" và vẽ khung (bounding box). Nó dùng anchor-free (không cần "mỏ neo" cố định – tự do dự đoán box bất kỳ kích thước) và decouple head (tách riêng đoán vị trí và đoán loại). Với mỗi "ô lưới" trên ảnh (khoảng 8400 ô cho ảnh 640x640 pixel), Head tính:
- Box: Tọa độ tâm (x,y), rộng/cao (w,h) – như vẽ khung vuông quanh mặt.
- Objectness: Xác suất có khuôn mặt (0-1, ví dụ 0.95 = 95% chắc chắn).
- Class probability: Xác suất là "khuôn mặt" (chỉ 1 loại ở đây).
Sau đó, NMS (Non-Maximum Suppression) lọc rác: Nếu 3 khung chồng lên nhau (do ánh sáng phản chiếu), giữ khung tốt nhất, loại 2 cái còn lại.
Giải thích dễ hiểu: Giống như trọng tài bóng đá: Head "thổi còi" (dự đoán penalty), NMS kiểm tra VAR (loại quyết định sai). Anchor-free như trọng tài tự do di chuyển, không bị ràng buộc vị trí cố định.
Ví dụ đời thường: Trong game PUBG Mobile, YOLOv8 (hoặc tương tự) phát hiện khuôn mặt người chơi để thêm hiệu ứng AR (mũ sắt ảo), NMS đảm bảo không vẽ khung kép lên cùng một người.
Ứng dụng gần gũi: Trong trường học Việt Nam, YOLOv8 có thể dùng cho hệ thống điểm danh tự động: Camera lớp học "nhìn" một lần, vẽ khung quanh 40 học sinh, gửi danh sách lên Google Classroom – tiết kiệm thời gian cho thầy cô, đặc biệt ở vùng sâu vùng xa.
3. Quá trình huấn luyện YOLOv8:
Huấn luyện YOLOv8 giống như dạy trẻ con nhận biết gia đình qua album ảnh: Bắt đầu với ví dụ đơn giản, dần phức tạp, khen thưởng khi đúng.
Các Bước Chi Tiết Với Ví Dụ:
Thu Thập Dữ Liệu: Lấy bộ sưu tập ảnh lớn như WIDER FACE (ảnh đám đông, lễ hội, thể thao). Dùng công cụ LabelImg (miễn phí) để vẽ khung quanh mặt và ghi nhãn "face".
- Ví dụ: Giống mẹ bạn chỉ "Đây là ảnh ông bà (vẽ khung), đây là ảnh chó nhà (không vẽ)". Augmentation (tăng dữ liệu): Lật ảnh, làm tối – như chụp ảnh em bé ngủ (pose khác) để trẻ quen.
Preprocess: Thu nhỏ ảnh về 640x640 (kích thước chuẩn, như khung tranh cố định), chuyển nhãn thành số (class=0 cho face, vị trí tâm=0.5 nghĩa là giữa ảnh).
- Liên hệ: Như sắp xếp album theo chủ đề, dễ tìm.
Huấn Luyện Chính: Dùng lệnh đơn giản
yolo train model=yolov8n.pt data=face.yaml epochs=100 imgsz=640(epochs=100 vòng học, imgsz=kích thước ảnh).- Optimizer: Như "huấn luyện viên" AdamW điều chỉnh tốc độ học (chậm lại khi gần đúng).
- Loss Function: "Phạt điểm" nếu sai – CIoU phạt box lệch (như vẽ khung quá rộng), BCE phạt đoán sai loại (nhầm xe là mặt).
- Mosaic Augmentation: Ghép 4 ảnh thành 1, như vẽ tranh ghép 4 bức ảnh gia đình thành 1 siêu ảnh – giúp học đa dạng.
- Ví dụ thực tế: Huấn luyện trên ảnh học sinh Việt Nam (dataset custom từ trường THPT), model học nhận diện "khuôn mặt Á Đông" tốt hơn pretrained (mặc định từ ảnh phương Tây). Thời gian: 2 giờ trên laptop có GPU (như NVIDIA GTX), hoặc dùng Google Colab miễn phí.
Ứng dụng gần gũi: Các startup Việt như FPT AI dùng YOLOv8 huấn luyện trên dữ liệu địa phương để phát hiện khuôn mặt trong video giao thông – nhận diện tài xế mệt mỏi, giảm tai nạn đường phố.
4. Quá Trình Phát Hiện: "One Look" Trong Đời Sống Hàng Ngày
Inference (phát hiện) là "giai đoạn thi đấu": Ảnh vào, box ra chỉ trong 20ms (nhanh hơn chớp mắt).
 Nhận diện khuôn mặt với YOLOv8
Nhận diện khuôn mặt với YOLOv8
Bước Dễ Theo Dõi:
- Input: Thu nhỏ ảnh, normalize (chia 255 để số từ 0-1).
- Forward Pass: Chạy qua Backbone-Neck-Head một lần duy nhất.
- Post-Processing: Filter confidence >0.25, NMS loại chồng.
- Ví dụ: Trong Shopee Live, YOLOv8 phát hiện mặt streamer, thêm sticker vui – mượt mà không lag.
Code thử trên Colab:
from ultralytics import YOLO
model = YOLO('yolov8n-face.pt') # Tải "siêu anh hùng"
results = model('anh_tuoi.jpg', conf=0.25) # Nhìn một lần
results[0].show() # Xem kết quả!
Chỉ 4 dòng, bạn có thể thử với ảnh selfie!
Ứng dụng gần gũi: Trong bệnh viện, YOLOv8 kết hợp tracking (theo dõi qua frames) để đếm số bệnh nhân chờ khám, giảm ùn tắc hành lang – đặc biệt hữu ích ở Việt Nam với dân số đông.
5. Ưu Nhược điểm và tương lai của YOLOv8
Ưu điểm mở rộng:
- Tốc độ: 40-60 FPS, lý tưởng cho video TikTok (Nano variant chỉ 3 triệu tham số, nhẹ như app Candy Crush).
- Linh hoạt: Xử lý occlusion (che khuất) tốt – ví dụ phát hiện mặt đeo khẩu trang trong chợ Bến Thành.
- Dễ học: Ultralytics có docs tiếng Việt cộng đồng, học sinh có thể train model cuối tuần.
Nhược điểm:
- Tài nguyên: Phiên bản Large cần GPU mạnh (như chơi game nặng), không phù hợp điện thoại cũ.
- Đạo đức: Có nguy cơ bias (thiên vị) nếu dataset thiếu đa dạng – ví dụ kém nhận diện da màu.
- Ví dụ: Giống smartphone cao cấp: Xịn nhưng đắt; giải pháp: Dùng variant Nano cho app Việt như Zalo.
Phân tích ứng dụng gần gũi:
- Giải trí: TikTok/Shopee dùng YOLOv8 cho filter AR – tăng tương tác 30%, giúp creator kiếm tiền dễ hơn.
- An ninh gia đình: Camera Nest (Google) tích hợp YOLOv8 gửi alert "Có người lạ trước cửa" – an tâm cho bố mẹ bận rộn.
- Giáo dục: Ở trường Việt, app điểm danh AI giảm thời gian 50%, cho thầy cô thêm giờ dạy STEM.
- Y tế: Phát hiện cảm xúc (vui/buồn qua mặt) trong tư vấn tâm lý online – hỗ trợ học sinh stress thi cử.
- Tương lai 2030: YOLOv9 (dự đoán) sẽ tích hợp VR, như "thử quần áo ảo" trên mặt bạn trong Shopee, hoặc robot gia đình nhận diện cảm xúc trẻ con để kể chuyện phù hợp.
Tóm lại, YOLOv8 không phải công nghệ xa xỉ – nó làm cuộc sống tiện lợi hơn, từ cười đùa trên mạng xã hội đến an toàn đường phố. Với bài viết này, hy vọng bạn thấy AI gần gũi như người bạn. Thử code trên Colab và chia sẻ kết quả nhé! Bạn áp dụng YOLOv8 vào đâu đầu tiên? Comment bên dưới!
Cảm ơn bạn đã kiên nhẫn đọc.
Nguồn tham khảo: Ultralytics YOLOv8 docs (2025), WIDER FACE benchmark.
Phạm Văn Tú
Giảng viên về lập trình Trí tuệ nhân tạo, Khoa học máy tính và Khoa học dữ liệu. Đam mê nghiên cứu về AI, xây dựng các mô hình AI và các lĩnh vực với về AI, Khoa học dữ liệu, mô hình ngôn ngữ...
No comments yet. Login to start a new discussion Start a new discussion